全局参数¶
在配置完知识库之后,系统会自动分配下列全局参数给语义库,用户可以根据需求修改下列参数:
全局参数URL
全局参数: https://kbnlp.cpolar.top/#/ucenter/globalconfig
参数列表
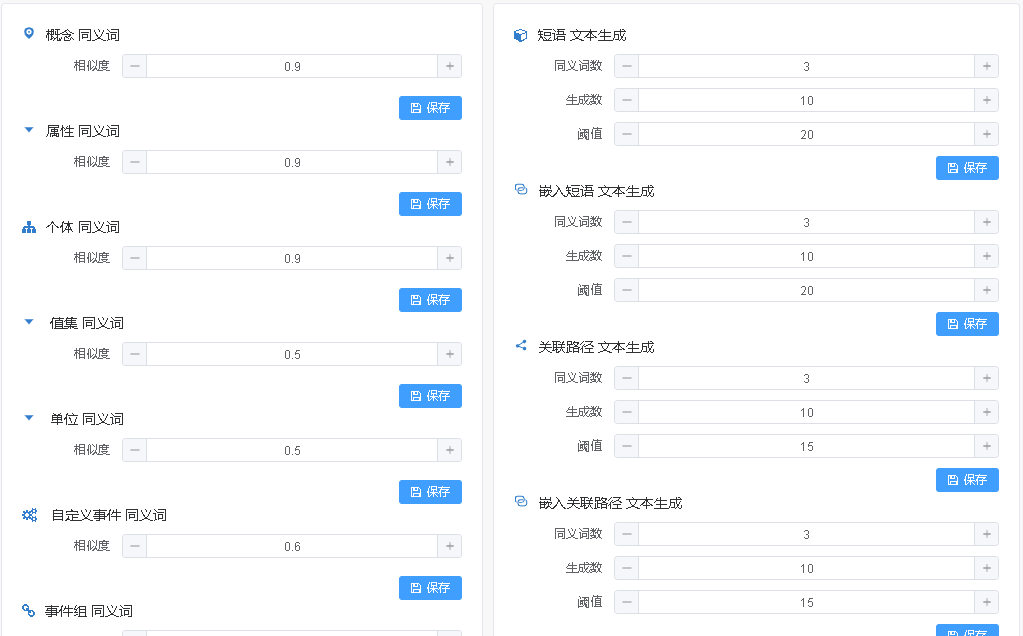
1. 同义词相似度
在定义语义基础阶段,需要为每个语义成分分配多个同义词。这些同义词有的可能相似度,有的没有相似度,对于没有相似度的同义词,系统提供默认的相似度值,这个默认值就在这里设置:
生成短语的语义对象类型包括:
- 概念
- 独立节点
- 个体
- 属性
- 值集
- 单位
生成句子的语义对象类型包括:
- 事件
- 事件组
相似度指标:相似度值为0~1之间的浮点数,该值越大,则对语义基础节点的表达越精确,即越接近基础节点的语义。
2. 文本生成参数:
生成短语文本的路径类型:
- 短语路径
- 嵌入短语路径
生成句子的路径类型:
- 关联路径
- 嵌入路径
- 复合路径
- 相似路径
在生成文本阶段,为了满足不同类型的需求,需要定量的控制文本的生成数量和质量。系统提供三个指标来保证这点:
同义词个数:使用同义词个数来控制生成文本的差异程度,同义词个数越多,则生成文本使用的词汇越丰富,文本字面相似度越低,对语义场的覆盖率也就越高。在诸如聊天应用场景中,对相同语义的不同表达方式文本的捕捉概率就越高。但过多的同义词个数也会导致算法生成文本数量急剧膨胀,降低生成效率。这里系统设置默认值为3,用户可以根据自身的需求调整该值的范围,建议小于10。
生成数:生成文本的总数,该数字越大,则生成文本的数量越多。这里系统设置默认值为10,用户可以根据自身的需求调整该值的范围。
阈值: 这里的阈值也可以理解为困惑度,是NLP(自然语言处理)中对生成文本的流利程度的一个典型指标。这个数字越小,说明生成文本的流利程度越高,即越接近人类自然语言的表达。这里系统设置的默认值20,它是个经验值,依赖于对语言模型大规模测试。该值会根据模型的规模或算法改变进行调整。
操作说明
%%{init:{'theme':'default', 'themeVariables':{'fontSize':'12px'}}}%%
graph LR
A[根据需求修改指定参数] --> B[点击该参数项下的保存按键] --> C[保存至数据库]